A loading computer is an effective and useful tool for the safe running of a ship. However, its output can only be as accurate as the information entered into it.
— MAIB, SAFETY FLYER Hoegh Osaka: Listing, flooding and grounding on 3 January 2015
引言
信用评分卡是一个通过对个人的信用数据进行评估进而法对其还款能力和还款意愿进行定量评估的系统。在消费金融行业,信用评分卡主要有三种(A卡、B卡、C卡):
- A卡(Application score card)申请评分卡,侧重贷前,一般用于预测客户的违约风险。
- B卡(Behavior score card)行为评分卡,侧重贷中,一般用于预测客户开户后一定时期内违约拖欠的风险。
- C卡(Collection score card)催收评分卡,侧重贷后,一般用于在帐户管理期,对逾期帐户预测催收策略反应的概率。
简言之,评分卡就是一个数据驱动的,用于衡量客户是好客户还是坏客户的一个工具。
本评分卡建模系列文章的初衷就是以经典的逻辑回归模型为主,完成一套标准申请评分卡的构建。本篇文章主要是对评分卡建模的数据进行分析,在此基础上确定预处理方案,并完成建模前的数据预处理。
1 数据选取(Sampling)
“巧妇难为无米之炊”。在机器学习中,数据和特征便是“米”,模型和算法则是“巧妇”。对于一个机器学习问题,数据和特征往往决定了结果的上限,而模型、算法的选择及优化则是在逐步接近这个上限。
所以说,数据是机器学习问题的基石,输入模型的数据必须是精确、干净的,所以这就需要进行数据预处理了。数据预处理前需要对样本数据中的变量进行分析,以确定数据预处理方案。
数据来源:www.kaggle.com:GiveMeSomeCredit
本项目使用了Kaggle 2011 年 GiveMeSomeCredit项目提供的数据作为本次评分卡建模的训练数据。GiveMeSomeCredit共包含15万个申贷人的过往个人信用信息,先来看一下数据字典。
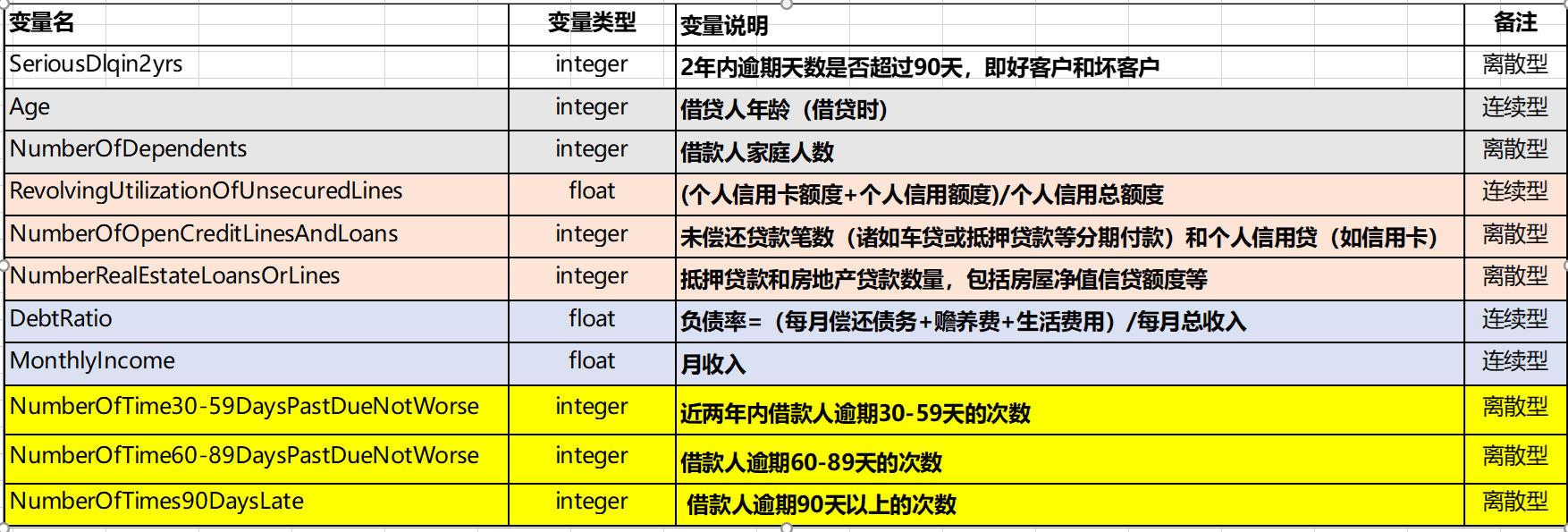
从数据字典来看,共包含11个字段,主要为借贷人的年龄、月收入、家庭人数以及信用逾期信息。
2 数据预处理
2.1 缺失值处理
1
2
3
4
5
# 读取数据
df=pd.read_csv('cs-training.csv')
# 删除无用的索引列
del df['Unnamed: 0']
df.info()
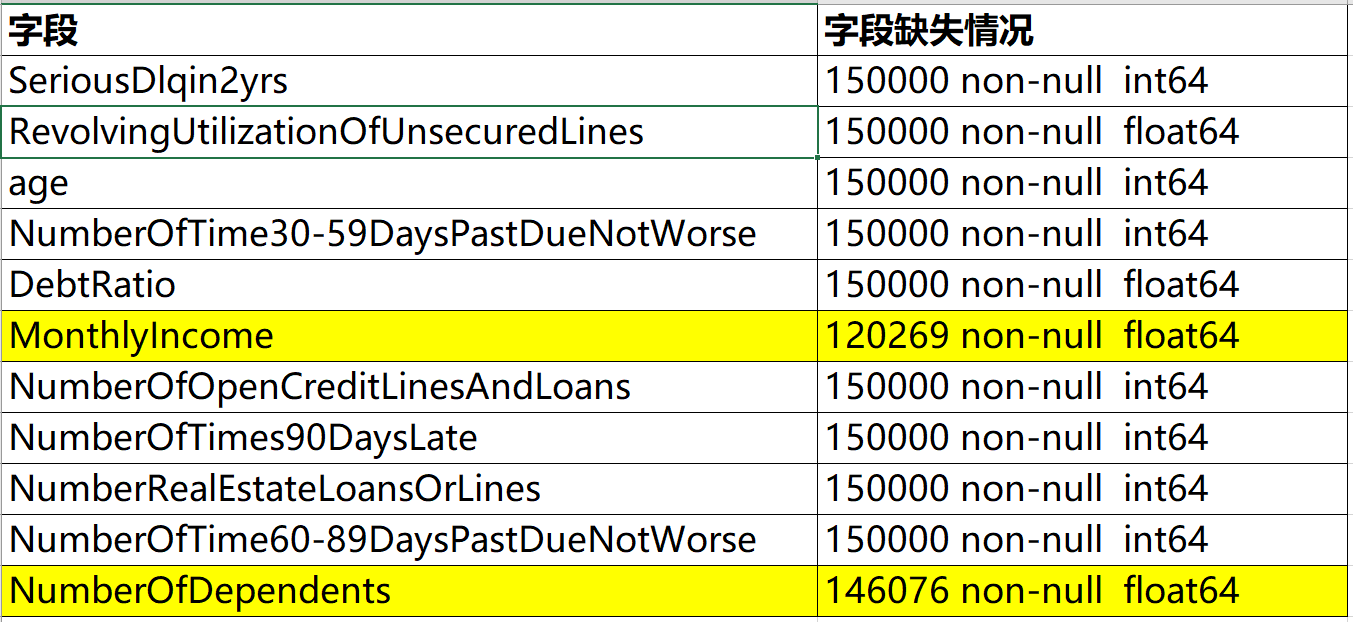
从 df.info() 返回 的信息来看 MonthlyIncome(月收入)列和NumberOfDependents(借款人家庭人数)列数据有缺失,其中 MonthlyIncome列缺失了近30000条数据,NumberOfDependents列缺失了近40000条数据。
使用 随机森林法对缺失值进行处理,了解随机森林法
2.1.1 对MonthlyIncome列使用随机森林法填补缺失值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
#随机森林法填补MonthlyIncome
MI_df=df.loc[:,'SeriousDlqin2yrs':'NumberOfTime60-89DaysPastDueNotWorse']
MI_known=MI_df[MI_df['MonthlyIncome'].notnull()]
MI_unknown=MI_df[MI_df['MonthlyIncome'].isnull()]
# 删除MI_know中的MonthlyIncome列,但不改变原有的MI_know中的数据,而是返回另一个dataframe:X_known来存放删除后的数据
X_known=MI_known.drop('MonthlyIncome',axis=1)
# y_known是一个series
y_known=MI_known['MonthlyIncome']
# 删除MI_unknown中的MonthlyIncome列,但不改变原有的MI_unknown中的数据,而是返回另一个dataframe:X_unknown来存放删除后的数据
X_unknown=MI_unknown.drop('MonthlyIncome',axis=1)
# 使用scikit-learn中的RandomForestRegressor
# """
# random_state:
# 此参数让结果容易复现。 一个确定的随机值将会产生相同的结果,在参数和训练数据不变的情况下。
# 有时候这种方法比单独的随机状态更好。
# n_estimators=100:决策树的个数,越多越好,但是越多性能就会越差,至少100左右
# max_depth: (default=None)设置树的最大深度,默认为None,这样建树时,会使每一个叶节点只有一个类别,或是达到min_samples_split。
# n_jobs=1:并行job个数。这个在ensemble算法中非常重要,尤其是bagging
# (而非boosting,因为boosting的每次迭代之间有影响,所以很难进行并行化),因为可以并行从而提高性能。
# 1=不并行;n:n个并行;-1:CPU有多少core,就启动多少job
# """
rfr=RandomForestRegressor(random_state=0, n_estimators=100, max_depth=3, n_jobs=-1)
rfr.fit(X_known, y_known)
df.loc[MI_df['MonthlyIncome'].isnull(), 'MonthlyIncome']=rfr.predict(X_unknown).round(0)2.1.2 对MonthlyIncome列使用随机森林法填补缺失值
2.1.2 对NumberOfDependents列使用随机森林法填补缺失值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#随机森林法填补NumberOfDependents
ND_df=df.copy()
ND_known=ND_df[ND_df['NumberOfDependents'].notnull()]
ND_unknown=ND_df[ND_df['NumberOfDependents'].isnull()]
# 删除MI_know中的NumberOfDependents列,但不改变原有的MI_know中的数据,而是返回另一个dataframe:X_known来存放删除后的数据
X_known=ND_known.drop('NumberOfDependents',axis=1)
# y_known是一个series
y_known=ND_known['NumberOfDependents']
# 删除ND_unknown中的NumberOfDependents列,但不改变原有的ND_unknown中的数据,而是返回另一个dataframe:X_unknown来存放删除后的数据
X_unknown=ND_unknown.drop('NumberOfDependents',axis=1)
# 使用scikit-learn中的RandomForestRegressor
rfr=RandomForestRegressor(random_state=0, n_estimators=100, max_depth=3, n_jobs=-1)
rfr.fit(X_known, y_known)
df.loc[ND_df['NumberOfDependents'].isnull(), 'NumberOfDependents']=rfr.predict(X_unknown).round(0)
2.2 异常值处理
数据建模前,一般在处理缺失值完成后,还需要对明显偏离大多数抽样数据的数值进行异常值处理,例如申请信用卡的客户的年龄一般应在16岁-100岁之间,如果不在这个区间则可以认为是异常值。
定位样本总体中的异常值通常采用离群值检测的方法, 离群值检测的方法有单变量离群值检测、局部离群值因子检测、基于聚类方法的离群值检测等方法。
本项目中数据维度比较简单,直接使用pandas的统计函数结合箱形图分析各个变量的异常,并进行处理。
箱形图(Box-plot)又称为盒须图、盒式图或箱线图,是一种用作显示一组数据分散情况资料的统计图,能够清晰直观地观察到异常值信息, 它能显示出一组数据的最大值、最小值、中位数及上下四分位数
箱子的中间一条线,是数据的中位数,代表了样本数据的平均水平。 箱子的上下限,分别是数据的上四分位数和下四分位数。这意味着箱子包含了50%的数据。因此,箱子的宽度在一定程度上反映了数据的波动程度。 在箱子的上方和下方,又各有一条线。有时候代表着最大最小值,有时候会有一些点分布在线外,一般而言这些就可以理解成“异常值”了。
2.2.1 变量异常值分析与处理
2.2.1.1 个人信息变量分析
个人信息and贷款次数包含两个变量:年龄和家庭人数。
虽然我们将年龄定义为了连续性变量,其实这里也可以和家庭人数一样,将其作为离散型变量来处理。
需要注意的是:家庭人数这个变量有缺失值 ,我们在上面已经使用随机森林法填补了这些缺失值。
| 变量名 | 变量类型 | 变量说明 |
|---|---|---|
| Age | integer | 借贷人年龄(借贷时) |
| NumberOfDependents | integer | 借款人家庭人数 |
先来看下这两个变量的描述性统计结果,很直观地发现以下问题:
- 年龄有为0岁和大于100岁的样本
- 家庭人数无明显异常
| 变量名 | Total | Min | Max | mean | std |
|---|---|---|---|---|---|
| age | 150000 | 0 | 109 | 52.30 | 14.77 |
| NumberOfDependents | 150000 | 0 | 20 | 0.75 | 1.10 |
再来看下年龄的箱形图分布:
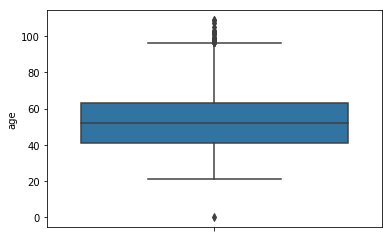
通过age的箱形分布图结合样本数据我们发现了大于100岁和0岁的样本,另外对样本数据进行观察可以发现最小年龄为21岁,所以直接剔除这些年龄异常的样本即可。
2.2.1.2 个人信贷信息变量分析
个人信贷信息变量包含一个连续型变量RevolvingUtilizationOfUnsecuredLines 和两个离散型变量:NumberOfOpenCreditLinesAndLoans、NumberRealEstateLoansOrLines
| 变量名 | 变量类型 | 变量说明 |
|---|---|---|
| RevolvingUtilizationOfUnsecuredLines | float | (个人信用卡额度+个人信用额度)/个人信用总额度 |
| NumberOfOpenCreditLinesAndLoans | integer | 未偿还贷款笔数(诸如车贷或抵押贷款等分期付款)和个人信用贷(如信用卡) |
| NumberRealEstateLoansOrLines | integer | 抵押贷款和房地产贷款数量,包括房屋净值信贷额度等 |
其中 RevolvingUtilizationOfUnsecuredLines 是一个百分比型的连续变量,表示(个人信用卡额度+个人信用额度)/个人信用总额度,原则上应该是分布在[0,1]之间。
| varname | total | max | Min | mean | 标准偏差 |
|---|---|---|---|---|---|
| RevolvingUtilizationOfUnsecuredLines | 150000 | 0.000 | 50708.000 | 6.048 | 249.755 |
通过对该列的分却发现,实际上该列的最大值为50708,中位数为 6.048438,这说明此列有大于1的值 。
进一步分析发现,共有3321个RevolvingUtilizationOfUnsecuredLines列值大于1的样本。
处理方法:直接剔除
对于离散型变量:NumberOfOpenCreditLinesAndLoans、NumberRealEstateLoansOrLines,先来看一下它们的描述性统计结果,无异常。
| 变量名 | Total | Min | Max | Mean | Std |
|---|---|---|---|---|---|
| NumberOfOpenCreditLinesAndLoans | 150000 | 0 | 58 | 8.45 | 5.146 |
| NumberRealEstateLoansOrLines | 150000 | 0 | 54 | 1.02 | 1.130 |
再来看一下这两个变量的箱形图分布
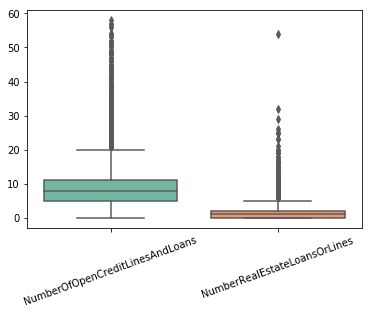
从这个箱形图结果来看,虽然有一部分样本波动较大,但是有超过20笔包含分期付款在内的未偿还贷款笔数也是在情理之中,所以对于这两个变量认为其无异常值。
2.2.1.3 个人收入与负债信息变量分析
个人收入与负债信息变量包含以下两个连续型变量:
| 变量名 | 变量类型 | 变量说明 |
|---|---|---|
| DebtRatio | float | 负债率(每月偿还债务+赡养费+生活费用)/每月总收入 |
| MonthlyIncome | float | 月收入 |
先看下 这两个变量的描述性统计分析结果:
| 变量名 | Total | Min | Max | Mean | Std |
|---|---|---|---|---|---|
| DebtRatio | 150000 | 0 | 329664 | 353.01 | 2037.82 |
| MonthlyIncome | 150000 | 0 | 3008750 | 6034.05 | 12999.29 |
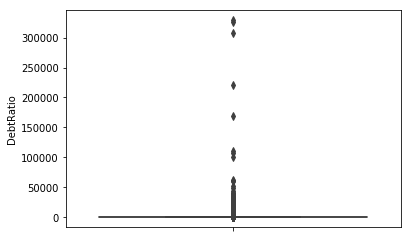
先来看DebtRatio, 个人负债率最大值竟然为33万,这个简单是非常的不可理喻。
结合原始样本探究了下,结果如下:
| item | num |
|---|---|
| 负债率 > 1 | 35137 |
| 负债率 > 100 | 24380 |
| 负债率 > 1000 | 16892 |
| 负债率 > 5000 | 1481 |
在请教了风控人员后,决定,将DebtRatio列大于5000的样本全部作为异常值剔除掉。
再来看MonthlyIncome,即个人月收入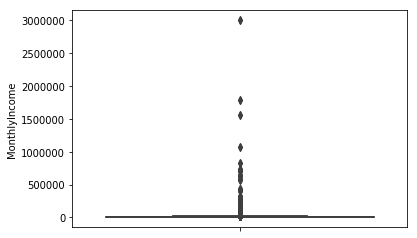
从箱形分布图来看,个人月收入主要集中在100万以下,结合原始样本探究了下,结果如下:
| item | num |
|---|---|
| 个人月收入 > 2万 | 2103 |
| 个人月收入 > 5万 | 301 |
| 个人月收入 > 10万 | 70 |
可见,对于月收入超过10万的样本,数据少,而且并不具备代表性,因此最后将MonthlyIncome列大于10万的样本全部剔除。
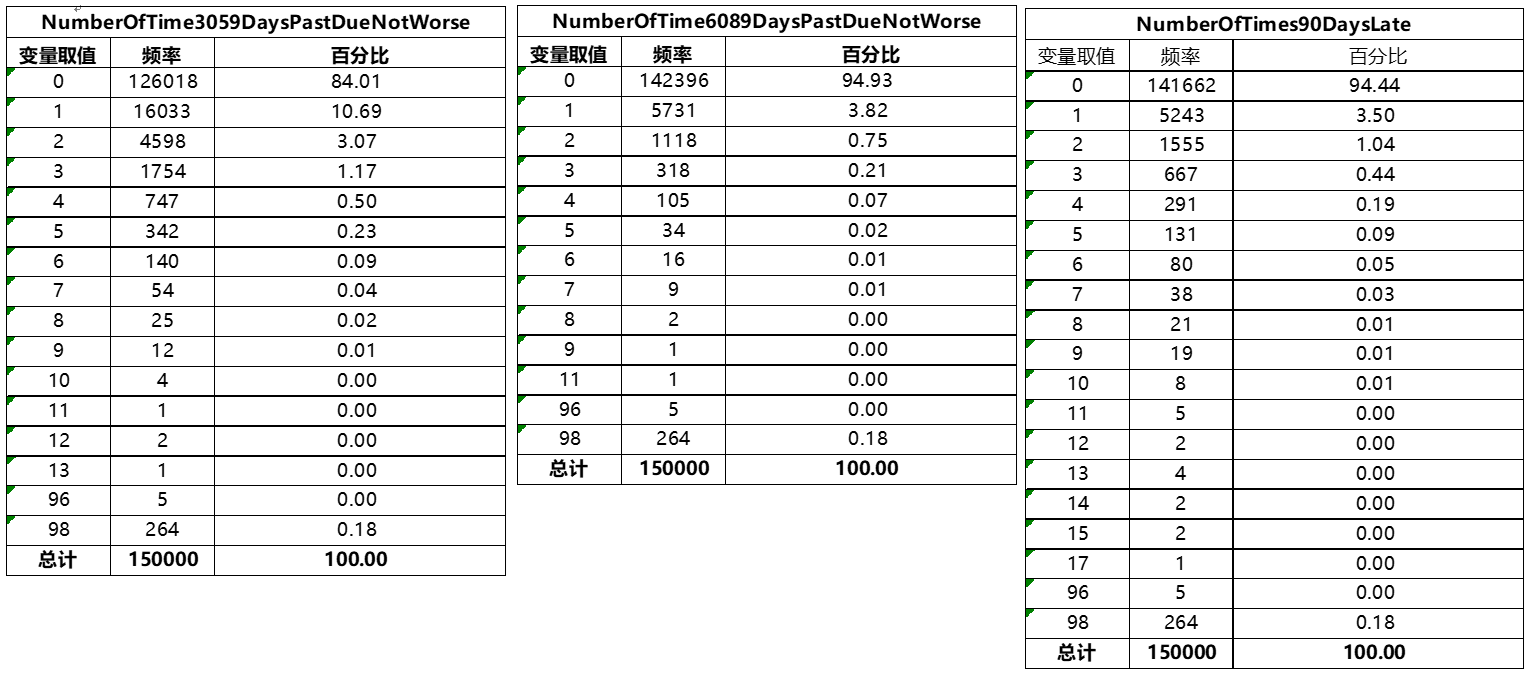
2.2.1.4 借款人近两年逾期次数变量分析
借款人近两年逾期次数包含下面三个离散型变量:
| 变量名 | 变量类型 | 变量说明 |
|---|---|---|
| NumberOfTime30-59DaysPastDueNotWorse | integer | 借款人逾期30-59天的次数 |
| NumberOfTime60-89DaysPastDueNotWorse | integer | 借款人逾期60-89天的次数 |
| NumberOfTimes90DaysLate | integer | 借款人逾期90天以上的次数 |
先来看一下这三个变量的描述性统计结果
| 变量名 | Total | Min | Max | Mean | Std |
|---|---|---|---|---|---|
| NumberOfTime3059DaysPastDueNotWorse | 150000 | 0 | 98 | .42 | 4.193 |
| NumberOfTime6089DaysPastDueNotWorse | 150000 | 0 | 98 | .24 | 4.155 |
| NumberOfTimes90DaysLate | 150000 | 0 | 98 | .27 | 4.169 |
再来看下这三个变量的频数分布情况,从频数分布来看,这三个变量的取值集中在[1,20],只有0.18%的样本取值为96或98。
处理方法:将这三个变量取值在90以上的样本中的逾期次数全部替换为0
2.2.2 变量异常值处理代码
2.2.2.1 异常值处理规则汇总
在2.2.1章节逐一分析了样本数据中的变量,并会对有异常值的变量设置了相应的异常值处理方案,总结下:
age列,剔除不在(0,100)区间内的样本RevolvingUtilizationOfUnsecuredLines列,即个人已获取信贷额度比例,剔除不在[0,1]区间内的样本DebtRatio列,即个人负债比例,剔除所有大于5000的样本MonthlyIncome列,即个人月收入,剔除所有大于10,0000的样本- 对于借款人近两年逾期次数的三列变量,即
NumberOfTime30-59DaysPastDueNotWorse,NumberOfTime60-89DaysPastDueNotWorse,NumberOfTimes90DaysLate,将所有大于90的样本的取值用0来替换
2.2.2.2 异常值处理代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
# age列,剔除不在(0,100)区间内的样本
df = df[(df['age']>0) & (df['age'] < 100)]
# RevolvingUtilizationOfUnsecuredLines列,剔除不在[0,1]区间内的样本
df =df[(df['RevolvingUtilizationOfUnsecuredLines']>=0)&(df['RevolvingUtilizationOfUnsecuredLines']<=1)]
# DebtRatio列,即个人负债比例,剔除所有大于5000的样本
df = df[df['DebtRatio']<=5000]
# MonthlyIncome列,即个人月收入,剔除所有大于10,0000的样本
df = df[df['MonthlyIncome']<=100000]
# 对于借款人近两年逾期次数的三列变量,将所有大于90的样本的取值用0来替换
for column in ['NumberOfTime30-59DaysPastDueNotWorse','NumberOfTime60-89DaysPastDueNotWorse','NumberOfTimes90DaysLate']:
df[df[column]>90] = 0
# 去重
df.drop_duplicates(inplace=True)
3 结语
经过以上步骤,我们的数据预处理工作就算基本完成了。
一般而言对于一个数据建模项目来说,数据预处理的工作要占整个项目的80%左右,如果这个建模是用于生产环境,或许还会更久。
因为只要输入模型的数据的质量得到了保证,模型预测出的结果才可能准备,不然就真的是Garbage in, garbage out了。
好了,花了几个晚上终于完成了这部分数据的预处理工作,接下来就可以开始着手构建模型了。